

Introduction
Several vulnerabilities with the popular ASP.NET web application add-on Telerik UI for ASP.NET AJAX have become a frequent source of “easy-wins” for operators at BLS. Discovery and exploitation are usually straightforward, and they result in remote code execution on public-facing IIS servers.
Although use of the Telerik UI library has declined somewhat in the wake of several severe vulnerabilities, it’s hard to find an organization with IIS servers that doesn’t have at least an application or two using it. Even though patches have been available for years, we still encounter vulnerable versions on a regular basis in 2022.
There has been a significant amount research into this particular library already, and there are existing tools to detect and exploit it. However, after finding some unusual edge cases where existing tooling failed, we decided to take a deep look into the library for ourselves.
Vulnerable Endpoints
The vulnerabilities revolve around a couple handler endpoints that interface with the Telerik.Web.UI.dll library. The vulnerable .dll can be found in the /bin folder of the application it is being utilized in. The URL to .dll mapping occurs in the application’s web.config, and looks something like this:
<handlers>
<add name="Telerik_Web_UI_DialogHandler_aspx" verb="*"
preCondition="integratedMode" path="Telerik.Web.UI.DialogHandler.aspx"
type="Telerik.Web.UI.DialogHandler" />
<add name="Telerik_Web_UI_SpellCheckHandler_axd" verb="*"
preCondition="integratedMode"
path="Telerik.Web.UI.SpellCheckHandler.axd"
type="Telerik.Web.UI.SpellCheckHandler"/>
<add name="Telerik_Web_UI_WebResource_axd" verb="*"
preCondition="integratedMode" path="Telerik.Web.UI.WebResource.axd"
type="Telerik.Web.UI.WebResource"/>
</handlers>The path variable in the config entry defines the URL that the the server will watch for, and the type parameter defines what class within the .dll the URL maps to.
Telerik.Web.UI.WebResource.axd?type=rau
The Telerik.Web.UI.WebResource.axd endpoint is the most well-researched and the most commonly exploited. It will not be the focus of this post, but it’s worth mentioning to provide context. The two main vulnerabilities here are CVE-2017-11317, an arbitrary-file upload made possible by a hard-coded default key. The next is CVE-2019-18935, an unsafe deserialization vulnerability. The deserialization vulnerability typically depends on the file upload; they need to be chained.
The real advantage CVE-2019-18935 provides is that the uploaded file can go anywhere on disk, whereas getting an RCE from a file upload usually requires write access to the web root. This increases the number cases where the 2017 CVE is exploitable.
For this endpoint, a blog post by Bishop Fox has really become the definitive guide for understanding and exploiting it. If you want to know more that should be your next stop. It’s also worth noting this blog post talking about the research around the 2019 deserialization vulnerability.
Telerik.Web.UI.DialogHandler.aspx
That leaves us with Telerik.Web.UI.DialogHandler.aspx. Note that it is deceptively not an .aspx file but just another handler mapping to the Telerik.Web.UI.dll library.
Note: Some web frameworks that include Telerik UI map this functionality to Telerik.Web.UI.DialogHandler.axd instead.
The dialog handler exploit is the less exploited but probably more fun little brother to the “rau” endpoint. The central issue is some poorly designed/implemented cryptography “protecting” a set of parameters that are used to initialize a file manager interface. It’s designated as CVE-2017-9248, and here’s the official CVE description:
Telerik.Web.UI.dll in Progress Telerik UI for ASP.NET AJAX before R2 2017 SP1 and Sitefinity before 10.0.6412.0 does not properly protect Telerik.Web.UI.DialogParametersEncryptionKey or the MachineKey, which makes it easier for remote attackers to defeat cryptographic protection mechanisms, leading to a MachineKey leak, arbitrary file uploads or downloads, XSS, or ASP.NET ViewState compromise.
This description is somewhat lacking, and doesn’t give a good sense of what’s going on. The big prize is getting access to the file browser, from which you can look around the file system and upload files. Although you can see directory listings and filenames, to our knowledge you can’t download anything so we’re actually not sure what the official description is referring to there. Regardless, as you may be aware, uploading a malicious .aspx to the webroot will result in code execution in most cases.
Unpatched Telerik UI Encryption
To get to the file upload, we’ve first got to get around the “encryption” protecting the dialog parameters. How does it work?
String with Dialog Parameters -> Base64 -> Rotating XOR -> Base64 (again).
Decryption is the opposite:
Un-base64 -> Rotating XOR -> Un-base64 again -> Parse the string for dialog parameters.
Needless to say – this is very unusual, and well… not good. Not only is a notoriously weak encryption scheme in use (rotating-key XOR), but it’s being used essentially as a form of authentication.
During decryption, the interaction between the XOR and the second base64 operation has some very interesting effects and is the source of the exploit as we’ll see soon.
At a high level, a couple basic cryptography principles explain where this encryption goes wrong:
Never ‘roll your own’ cryptography. This is a good example of the unexpected ways cryptography can go sideways when it’s deployed incorrectly. There’s almost no better example of breakable encryption than rotating key XOR, but that was even further undermined by the error messages leaking details about the decryption process. There’s a pretty large skill-gap between knowing enough to make cryptography functional and knowing enough to make it truly secure. It’s best to leave as much of the implementation as possible to the web framework or language being used.
Encryption is not authentication. Encryption is only meant to protect confidentiality, and any limited protection to integrity is an incidental side-effect of it. The success or failure of a decryption operation should not be used as a form of authentication.
To protect integrity, utilize hashing and signing. There are also encryption schemes that deliberately incorporate integrity protection alongside the encryption. A great example would be AES-GCM, which is encryption with built-in authentication.
The patched version of Telerik UI utilizes AES in CBC mode paired with HMAC256 to validate the integrity of the message before attempting decryption, which is mostly driven by encryption libraries built into C#. Although the implementation wasn’t perfect, this is a dramatic improvement.
Exploit Details
When we send a request to Telerik.Web.UI.DialogHandler.aspx, our encrypted dialog parameters get sent via the dp GET parameter. When they are decrypted, if something is wrong, we will receive an error message with the specific reason why. Since we are base64 decoding after we decrypt, we get a little information leak that tells us if what was decrypted is valid base64 or not.


It turns out, all these different error messages leak enough information about the process to completely decrypt the message and discover the encryption key. It is possible to use this information to continually reduce the possible values for the key through a series of systematic requests, and ultimately discover the entire key. In many ways, this closely resembles a padding oracle attack, but instead of abusing the AES block padding we are abusing the properties of base64 encoding.
A brief primer on base64 padding
Base64 encoding is the practice of mapping data, usually 8-bit characters, into sequences of 24 bits, which are then represented by a series of four 6-bit characters.
Storing text in base64 comes with some overhead cost. For each block of four base64 characters, we can represent (at most) three 8-bit characters (or 8-bit chunks of binary data). Base64 data exists at a 4:3 ratio compared to its unencoded form.

We also might have a situation where we need to represent just one or two characters. This is where padding comes in. The “=” character is used to represent padding in base64. If one character is being represented, “==” will be appended as the padding. If the base64 block is representing two characters, “=” will be appended.
Note: Not all base64 implementations use padding, but the one used by Telerik UI does.
dp_crypto
The existing tool for cracking the key is called dp_crypto. We have used this many times in the past, and when it works, it works well. However, we eventually discovered an instance where dp_crypto could not solve the whole key. It would get about half-way through and just get stuck. One thing we noticed about this key after solving it later, was that it wasn’t only hex characters like the others we’d seen. Instead, it appeared to be comprised of random characters within the ascii-printable range.
After extensive testing our conclusion was that for hex-only keys, the tool worked great, but for random ascii keys, it was a bit of a crap-shoot. The tool is making assumptions about the key and doing some optimizations that would occasionally cause it to follow a false branch that led to a dead-end. These optimizations could be turned down, and in some cases this would result in finding the key. Still others were completely unsolvable. In addition, even when it worked, the process was slow and made a significant number of http requests in the process.
We give a lot of credit to the tool’s author, there are some very clever things going on. To come up with what he did with nothing else to work from is notable. We’re spoiling the punchline a little, but building our tool relied heavily on a lot of the existing logic in dp_crypto.
SR Labs Blog Post
Confused by the strange half-solved key we set out to see if anyone else had encountered this or had another solution. That quickly led us to the blog post Achieving Telerik Remote Code Execution 100 Times Faster by Security Research Labs.
We were very impressed by the research they did. They, in fact, did identify a much more efficient technique for deducing the key. The blog post is well written, complete with lots of easy to understand graphics. They step through a tool they built and walk through the difference in the exploit technique compared with dp_crypto in detail.
However, they opted to not release the tool. Going through the details of a tool but not releasing it seemed a little odd to us. In their post teased that they used a “little trick” to get one of the more difficult obstacles of this exploit to work, but declined to describe how they did it, and we were interested to know.
“Note: If password includes “=” sign (which is a valid base64 character), there is a little trick to be made, which will not be covered in this blog post.”
We did eventually figure out how to deal with “=” in the password with a extra pain. We nevertheless give the authors a ton of credit for the concepts they come up with and their detailed descriptions of them, which we leaned on heavily.
dp_cryptomg
That brings us to the tool we are releasing: dp_cryptomg. Our goal when we started writing it was to attempt to implement the techniques described in the SR Labs blog post, which would hopefully help to retrieve our previously irretrievable key.
Although we never wanted to make a new tool (especially in the midst of an engagement), it seemed worth it given we’d net an RCE for the engagement and it’s a great opportunity to dive into a really unique and interesting cryptography problem.
Let’s take a closer look at the technical details of the tool. Our goal is to deduce the original key, which we do this one base64 “block” at a time. In the context of each block, we can solve individual characters of the key one at a time.
For each character, we can send a series of “probes”. The goal of each probe is to answer the following question:
Given these 4 bytes we’re sending you, after you decrypt them using your rotating XOR key, does the result equal valid base64 or not?
The final result for each probe is a Boolean value, which reveals a little more information about the key for that position. Specifically, we can narrow down the possible candidates for what the key at the same position could be.
By sending the probe and checking for the “Index out of range” error message, we will know whether the bytes in our probe end up being valid base64 or not after being XOR’d with the key.
We can determine ahead of time which key characters will produce a true result and which will produce a false result for a given probe and use this data to reduce the number of candidates of characters which could be the key. This is the essence of the exploit.
The following is a simplified simulation, which has been slowed down to help conceptualize the process.
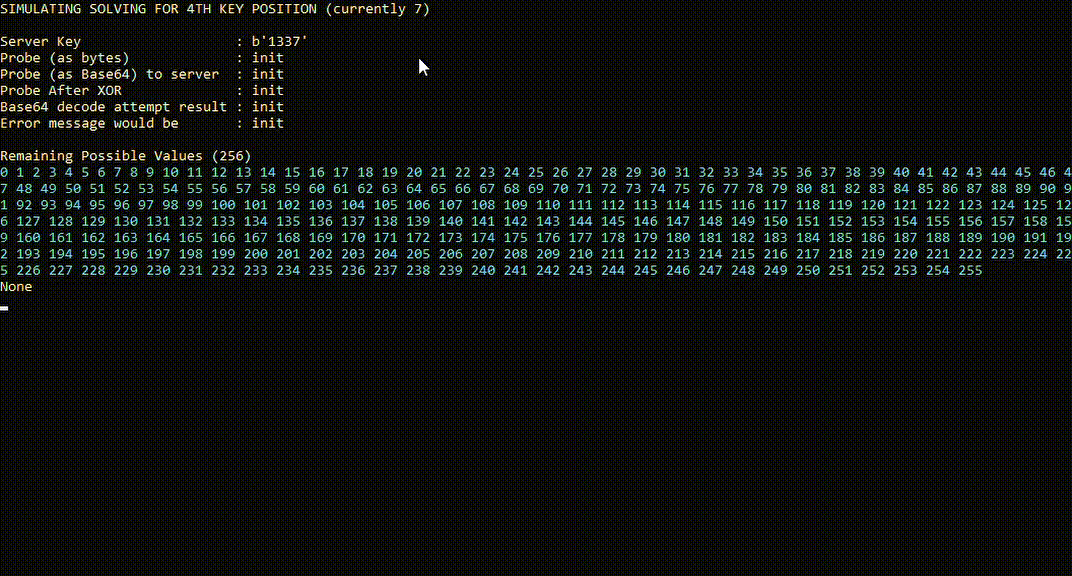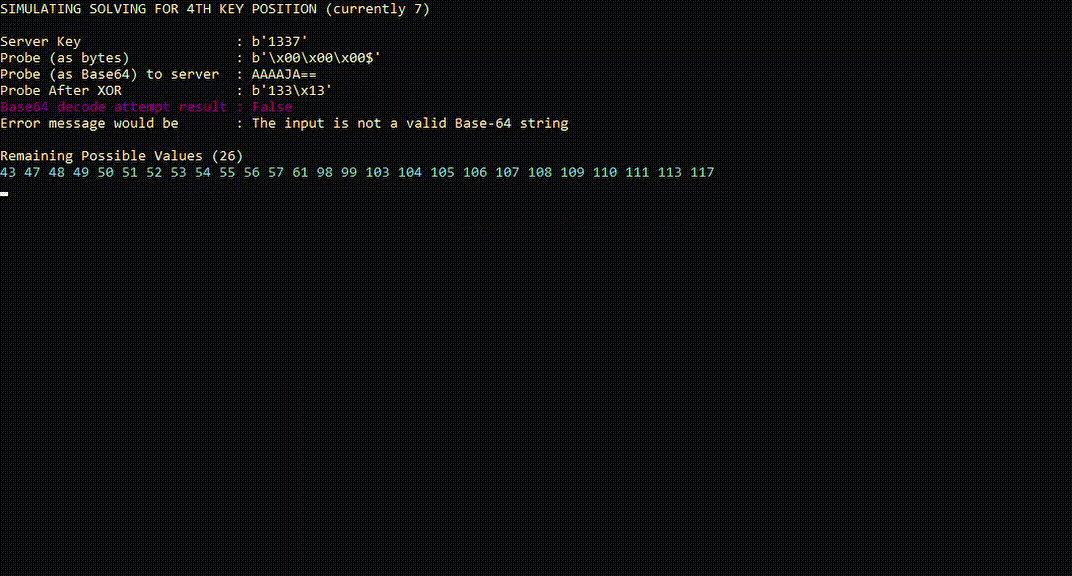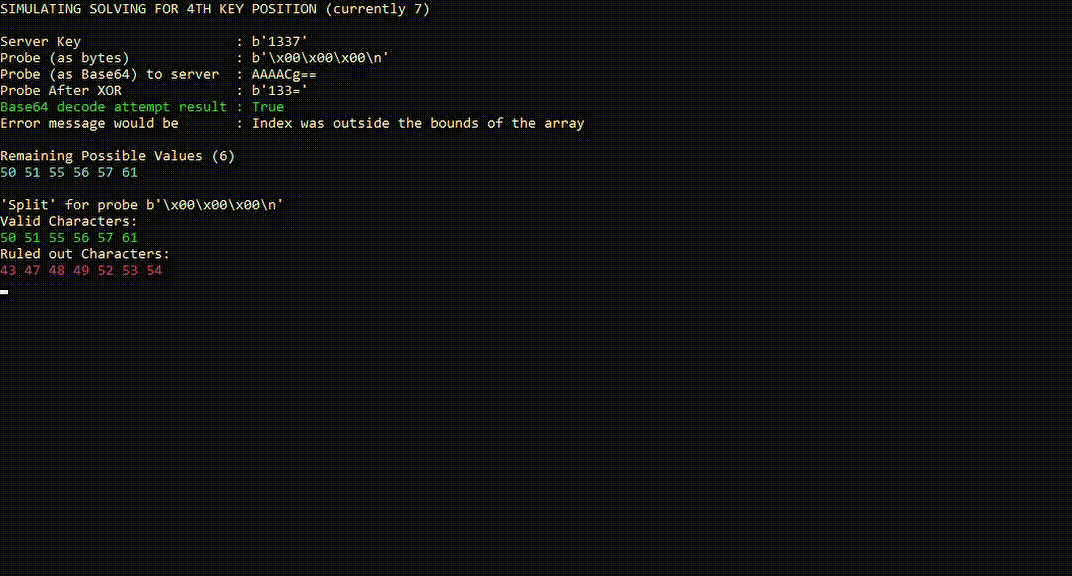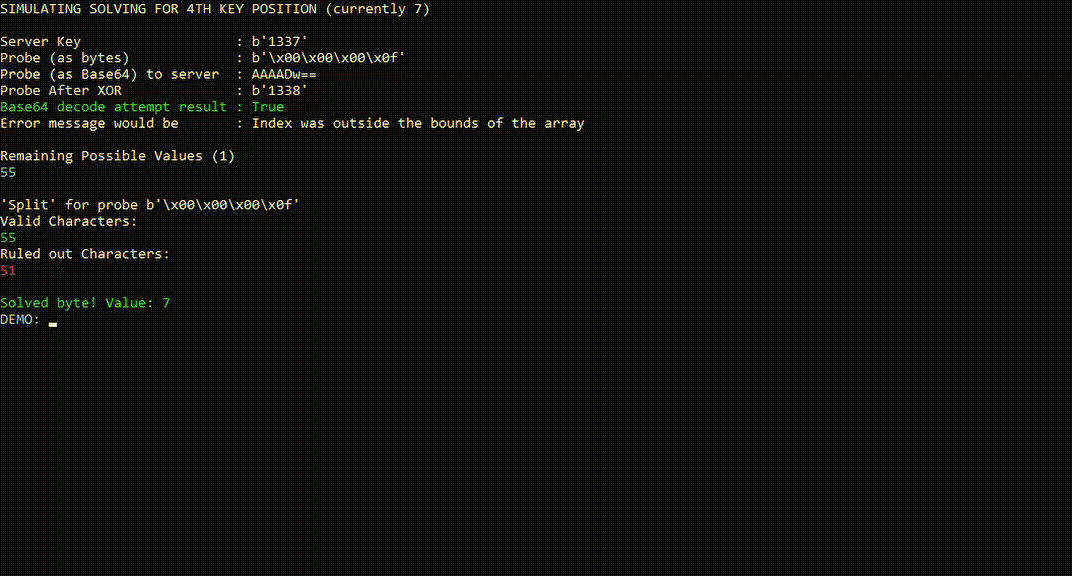
As we continue to send more probes, each “true” result will split the remaining set of possible characters. Eventually, we end up with a single possible character left, which we can be confident is the key character for that position.
We apply our partially solved key and move to the next character position and repeat the process for the rest of the block. One of the nice things about an XOR operation, is that sending 0x00 in a given position means we aren’t changing anything there. Therefore, we can effectively target the character we want to solve by sending 0x00 to the three positions we don’t want to affect.
The following chart breaks down the process that takes place for each individual probe as the server receives it.

The SR Labs blog post also describes this process in great detail and is worth a read if you still haven’t fully grokked the concept. They go on to describe how they found a few specific probe bytes that can be used to efficiently triage the characters into initial groups. However, the blog is less clear on how to select the correct probe bytes to take the process to a conclusion.
Choosing the Probes to Send
The SR Labs research discusses their strategy for choosing probes based on the likelihood of a given key character appearing in the key. They discuss the specific probe bytes that their research suggests are the most efficient in terms of doing some initial triage to what “bucket” the key character belongs to.
But what about after that? How do we keep determining the right bytes to send, all the way to the end where we end up with the solution? Our solution diverged from the SR labs technique here. The technique is not particularly elegant but was very effective: try every possible probe byte in an offline simulation and see which one splits the remaining possible values the most evenly.

The computational cost of “brute forcing” the optimal probe is negligible, and insignificant when compared with the network delay to the victim server.

The “=” Problem
It is worth noting that we only really learn something actionable on ‘true’ results. This is counter-intuitive, instinct would suggest that regardless of the result we can split them, selecting one bucket or the other. However, if we get a negative result, we must simply throw it away. Why? We can’t trust it because of the small possibility that are negative result was caused by the XOR randomly decrypting to an “=” in the wrong place. Only with a “true” result, which reaches down to where the plaintext is being parsed, can we make any definitive determinations about the key. This little annoying property of the “=” is easy enough to deal with, although it does reduce efficiency significantly.
The most challenging consequence of the unique properties of the “=” character occurs when the key itself contains one. This is because whenever it is used as a key in the same position as one of the \x00 bytes in our probe, it will result in a “=” (an XOR operation when one side is a null byte does not change anything).
So why exactly does that matter? Well, depending on at which position of the four byte base64 block the “=” key character is present in, the rules about whether “=” makes valid or invalid base64 change in according with base64 padding. For example, a “=” is always okay in the fourth position, sometimes ok in the 3rd position (only if the fourth is also a “=”) and never ok in the 1st or 2nd positions.
We eventually discovered that there are a special very specific series of probes than can help us find out if there are “=” characters in the key. We can use them to identify any equals signs in the key before we proceed as normal with the rest of the technique.
Note: The following section has been updated since release as we later discovered a rare edge case that can cause a false-positive when it comes to detecting a key byte being an equals.
If we send the following probes:
\x00\x00\x00\x01 - Result = False
\x00\x00\x00\x02 - Result = False
\x00\x00\x00\x00 - Result = True
\x00\x00\x00\x05 - Result = True
\x00\x00\x00\x16 - Result = True
\x00\x00\x00\x71 - Result = True
If the x01 and 0x2 probes are both they are both false (they both produce invalid base64), and the 0x00,x05,x16, and x71 probes are true, the key byte in question is a “=”. We can provably claim no other character will have the same combination of probe results.
With this pre-calculated set of probes, we can cover every possibility when it comes to an equals character being in the portion of the key we are trying to solve. This is best illustrated by looking at the functions implementing this.
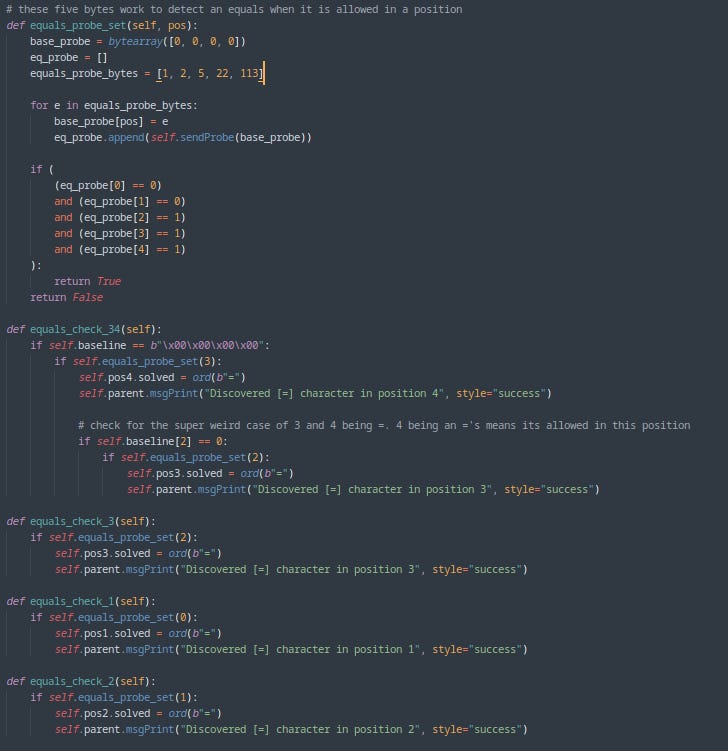
With this special case out accounted for, the block can be solved using probes generated by the findSplittingProbe function.
When all blocks finish, the key will be revealed and saved to a .txt file. Just as with dp_crypto.py, a link will also be generated with a pre-populated dp GET parameter, which is set up to load the file manager tool and is encrypted with the newly discovered key.
Note: There was a bug in versions before 0.1.3 where pre-2010 versions of Telerik where the key could be retrieved but could not be exploited because of subtle differences in how the dialog parameters were parsed. This has now been fixed. It may be the case that this is the first public tool that has ever been exploit exploit these versions of Telerik, as admittedly we did not have a pre-2010 .dll to test with during development.

A note on the fancy interface: There’s no particular reason it needed to be built this way, however it can be really helpful for understanding when doing exploits against cryptography to get some kind of visual indication of what’s going on. It is also just more fun to look at.
That said, if you want a more simplistic view, just run it with -s. This will provide a more traditional command-line output. Running with -S will even further reduce the output shown. Using these modes will also increase the speed of the exploit.
Telerik.Web.UI.SpellCheckHandler.axd
While our minds were deep inside the Telerik UI Library, we wondered about the third endpoint, shown in the configuration example at the beginning of this post, of which we had seen next to nothing written about. The Telerik.Web.UI.SpellCheckHandler.axd endpoint appeared to use the same DialogParameters scheme as the DialogHandler endpoint, with the same Base64 -> Rotating XOR -> Base64 encryption routine.
With some very minor adjustments to the existing tool (namely, the Telerik.Web.UI.SpellCheckHandler.axd endpoint wants a POST request, where certain other parameters must be present), we quickly realized we could easily extract the exact same key by reusing the same technique. dp_cryptomg will automatically detect if the provided URL is for the SpellCheckHandler.axd endpoint and adjust its behavior accordingly.
The DialogHandler endpoint is mostly dangerous because it allows for file uploads, which (usually) lead straight to RCE on web servers. What could the SpellCheckHandler offer? Well, to begin with the key used is exactly the same. You could use the SpellCheckHandler to get the key, and then exploit the DialogHandler with it. Of course, you also could have just used the DialogHandler so not is much gained there.
With that limited utility in mind, we set out to see what we could do if we only had access to the SpellCheckHandler endpoint. Such a scenario is not so far-fetched. The other two endpoints are very well-known, and some web application firewall security vendors have chosen to address the vulnerabilities by simply blocking repeated attempts to access them. In other cases, a developer might be made aware of the vulnerable Telerik endpoint and simply opt to remove their handlers and replace the functionality they were using, while neglecting the SpellCheckHandler endpoint because it is not mentioned anywhere.
The results of our efforts were admittedly somewhat disappointing but still worthy of discussion. We are still pulling on a few interesting threads that are not quite ready, but there is at least one we have ran all the way to ground.
Telerik.Web.UI.SpellCheckHandler.axd Arbitrary .txt file write
Once you know the Telerik.Web.UI.DialogParametersEncryptionKey key, it is simple to decrypt and re-encrypt dialog parameters. With the SpellCheckHandler.axd endpoint, the encrypted dialog parameters are sent in the Configuration POST parameter. We have included a simple utility in our GitHub repo (dp_manual_crypt.py) which can be used to manually encrypt, decrypt, and modify the encrypted dialog parameters for both endpoints, as depicted in several screenshots to follow.

As an example, with the key set to DEADBEEFDEADBEEFDEADBEEFDEADBEEF our Configuration parameter value ends up as follows:
FgItLiYCKTAmKAc9JxMHLiACJjcQKAM1J3cUNw8GPRQhKwMuGAAhESd0MR0RKwcuCXQLNxs/CxUddAcdEyshHwkDCysYACEBHXQXMBAoMRAJdQs3Gy4hch0/NQYgAj0wIHUHLxgAC3cndhMyIBY9AR0SOT4YFjI8CAMTPSYSEHERdgMoIAI9AiUCFy4jdAc/JnYbNBgCEz8IABssIA0LKggBCDcPLzEEJSgHcBQdDzUIABssIA0LKggBADcULiERJ3QxHRErBy4hERcdFSkhDCATGxIjdhMQCXULNxsuIXIWAgcMFCg1LgkCKSsbKHQVJ3QxHREdExwTAik2
When we decrypt this with the DEADBEEF key, we can see how the parameters are constructed:
DictionaryPath,False,0,QzpcdGVsZXJpa3Rlc3RcQXBwX0RhdGFcUmFkU3BlbGxc;AllowAddCustom,False,3,True;SpellCheckProvider,False,2,2;AjaxUrl,False,0,VGVsZXJpay5XZWIuVUkuU3BlbGxDaGVja0hhbmRsZXIuYXhk
The format for each parameter being used is as follows:
ParameterName,Boolean,Integer,Base64EncodedValue;
Then, each parameter is separated by a semicolon.
We can safely ignore the Boolean value; it is just used to defined whether the parameter is an array or not. The integer defines what data type the parameter is:
0 for string
1 for int
2 for Enum
3 for Bool
4 for DateTime
Note: These particular base64 decoded values end up being C:\teleriktest\App_Data\RadSpell\ for DictionaryPath and Telerik.Web.UI.SpellCheckHandler.axd for AjaxUrl.
These are not the only parameters that can be used, and by having a quick look at the decompiled Telerik UI .dll we can see what our options are for the SpellCheckHandler endpoint.

The one we are interested in here is the CustomDictionarySuffix. This parameter is used to help define where custom word lists get saved on the file system. These word lists are created or appended to when a user uses the “add to dictionary” functionality within the spellcheck editor.

This value in this parameter is concatenated into the path of the custom dictionary file. There is no sanitization or validation of the encrypted parameters, as a result we can use directory traversal characters to erase the beginning of the path and choose both the file path and name of the file. The only thing which can’t be changed is the .txt extension, which is appended onto the end of the string.
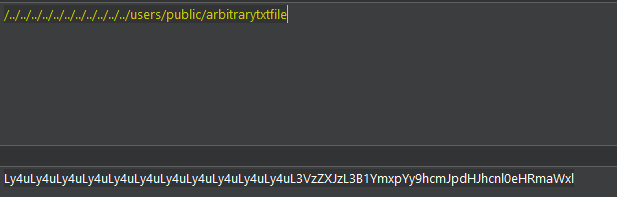
We then base64 encode this value and encrypt it back into the dialog parameters along with all the existing values.

The encrypted dialog parameters are added to a request to the SpellCheckHandler endpoint with CommandName set to AddCustom and CommandArgument set to the text we wish to write to the file. Note that it is also possible to write binary data using this method, by simply URL-encoding any non-standard bytes.

If the file is not already present, it will be created. If it exists, the content will be appended to it.
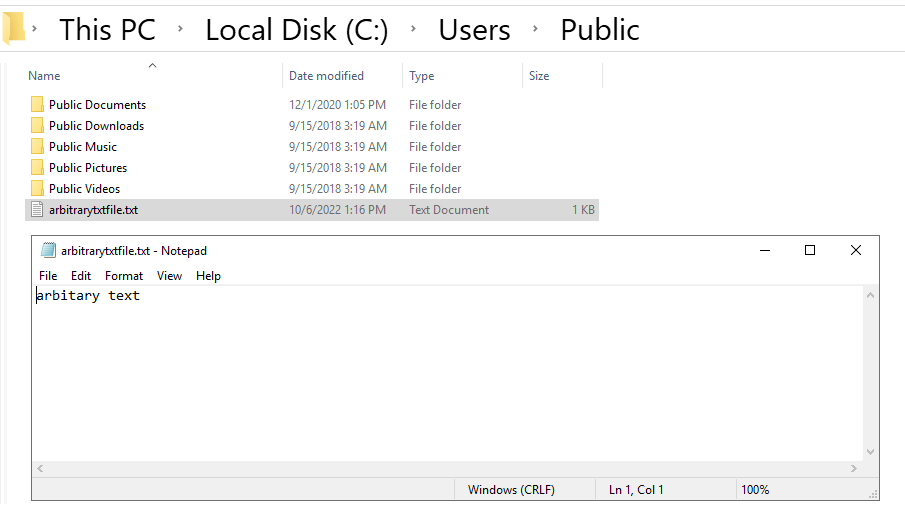
Of course, the fact that we can only write .txt files is a huge caveat and significantly reduces the impact. By itself, it is of little to no value outside of a denial of service attack by way of filling the server’s disk with junk. However, it is important to remember that getting arbitrary content onto the disk of a system is often a critical step in larger attacks. Consider a local file include (LFI) vulnerability; in such a case the .txt file can elevate the LFI into remote code execution.
There may also be specialized applications running on a server which is also using Telerik UI that performs some special action with .txt files in a particular directory.
Summary and Conclusions
We have improved on existing tooling surrounding CVE-2017-9248, increasing the scope of the exploit to cover vulnerable but previously unexploitable systems. We took a deep-dive into a few of the more challenging aspects of making the exploit work properly.
The Telerik.Web.UI.SpellCheckHandler.axd finally gets some attention, and with dp_cryptomg it can now be used to retrieve the DialogParametersEncryptionKey as well. We highlighted an interesting abuse specific to the SpellCheckHandler, albeit one with a limited use case.
It is worth mentioning that, although all of the issues discussed in this post are patched, many of the underlying coding mistakes were not. For example, rotating XOR encryption was replaced with a standard AES-CBC implementation, but it was implemented with a static initialization vector. This is still a vast improvement but is a pretty clear violation of accepted best practice and potentially opens the door for some fascinating exploits.
All of lack of sanitization of user-input, and path-traversal bugs are still present even in fully patched versions, they are just locked behind the new encryption. We believe there are more bugs to discover in this library, including within versions fully patched today. In fact, based on our current research we believe this blog will likely end up with a couple sequels. We cannot divulge details yet, but there is certainly more research to share in the near future, stay tuned.