


Regardless of how it may be portrayed on screen or in print, Offensive Security Testing can be extremely tedious and unforgiving. It requires organization, discipline, patience, system-of-systems thinking, and a multi-threaded intellect. Offensive Security Engineers have always pushed to automate at least a portion of their test methodologies for a cleaner, more-consistent, and detail-oriented approach. To that end, a thriving community has produced amazing tooling over the years; game-changing work that includes NMAP, Hydra, Metasploit, BurpSuite, aMASS, Impacket, masscan, Ghidra, Nikto, and the list goes on. We have heard whispers of “fully automated penetration tests” and “fully automated red teaming”, but nothing has ever really materialized and impacted our community in the same way as the semi-autonomous but ultimately operator-driven tools that we all use every day.
Then came the LLMs.
Multiple companies and individuals hit the ground running with LLM-augmented and fully-automated test suites. Some have even had a significant degree of success [1][2]. Many of us in this community have built our livelihoods around providing Offensive Security Testing, usually with really smart humans supported by well-built tools. It feels like something very exciting is happening right now with the tools that support those humans, though. Agentic coding can turn a simple chat-based LLM into a partner that lives in your terminal with you and can run your entire stack, as long as you can get past that whole “existential threat” question. LLMs are now and will continue to be incredible catalysts for change, but with that change inevitably comes complex and gnarly new problems to solve.
In the spirit of building, breaking, and bending new technologies to our will, a BLS operator has created red-run. It is an Offensive Security Testing Framework designed to run on top of Claude Code. It took ~2 weeks to build and required a shitload of tokens and at least one all-nighter. If we learned anything, it’s that the next few years are going to be exciting (and terrifying). As a working prototype, it’s far more capable than any of us thought it would be.
red-run is a Claude Code project that combines skills, MCP servers, and agents with routing logic that guides Claude and an operator through the phases of a targeted attack against IT infrastructure. It is an offensive security toolkit that no doubt pales in comparison to the sophisticated LLM-powered tooling that nation-state level threat actors already have in their arsenal.
Why?
But wait… Claude Code can already do this, with no skills required. Why make red-run?
red-run levels up Claude Code for Offensive Security operations:
Customizable skill library with semantic RAG retrieval.
Automated engagement state tracking, logging, and evidence gathering.
Persistent shell and interactive tool sessions that can be shared between agents.
Headless browser automation with Playwright.
Offsec-aware agent routing and task parallelization suggestions.
Self-improvement through retrospectives.
Plus, it is just so damn fun to hack and iterate with Claude Code. It is an accelerator. Tools like Claude Code and other “AI” coding agents will likely become requirements for any serious Offensive Security team. Without them, you will simply fall behind. Remember - the bad guys have this stuff too.
What?
Let’s zoom out for a moment.
A Large Language Model’s (LLM) context window is the amount of text that it can consider in its memory at one time. Think of the context window like volatile memory that is measured in tokens rather than gigabytes. A single token is roughly equivalent to three-quarters of a word [3].
Claude skills are markdown files that are loaded into context when called upon. Skills tell Claude how to do things the way you want them done. Claude already knows how to do just about everything. It can research. It can reason. It can troubleshoot. It can iterate. It can hack. The trick is getting it to do things in the correct way, in the proper sequence, and with accountability.
When a Claude Code session approaches its context limit, the context window is automatically compacted (summarized, essentially). This is not good for extended sessions where you have gained initial access, moved laterally, and started privilege escalation when, suddenly, your context window is compacted and critical earlier information is lost.


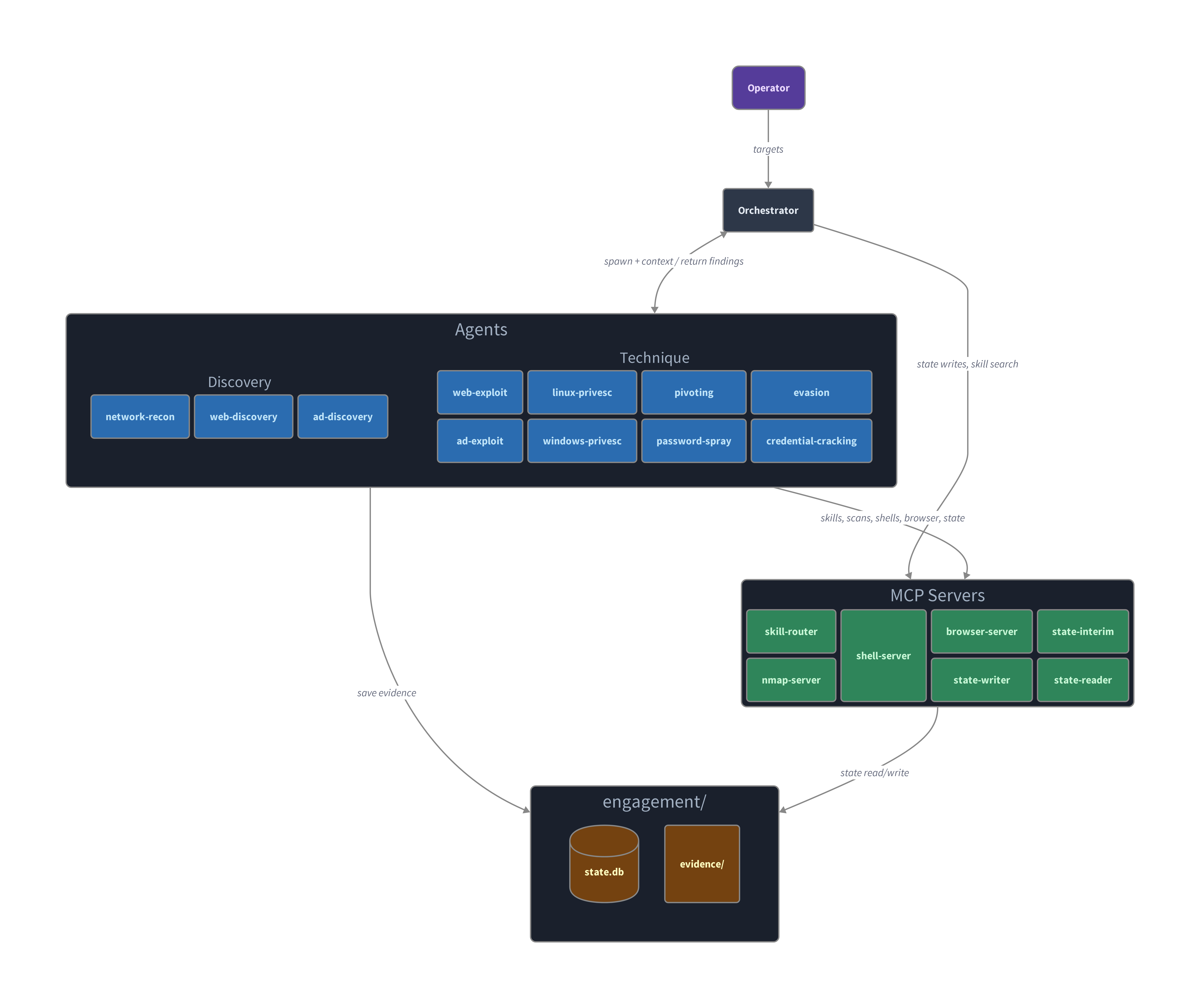
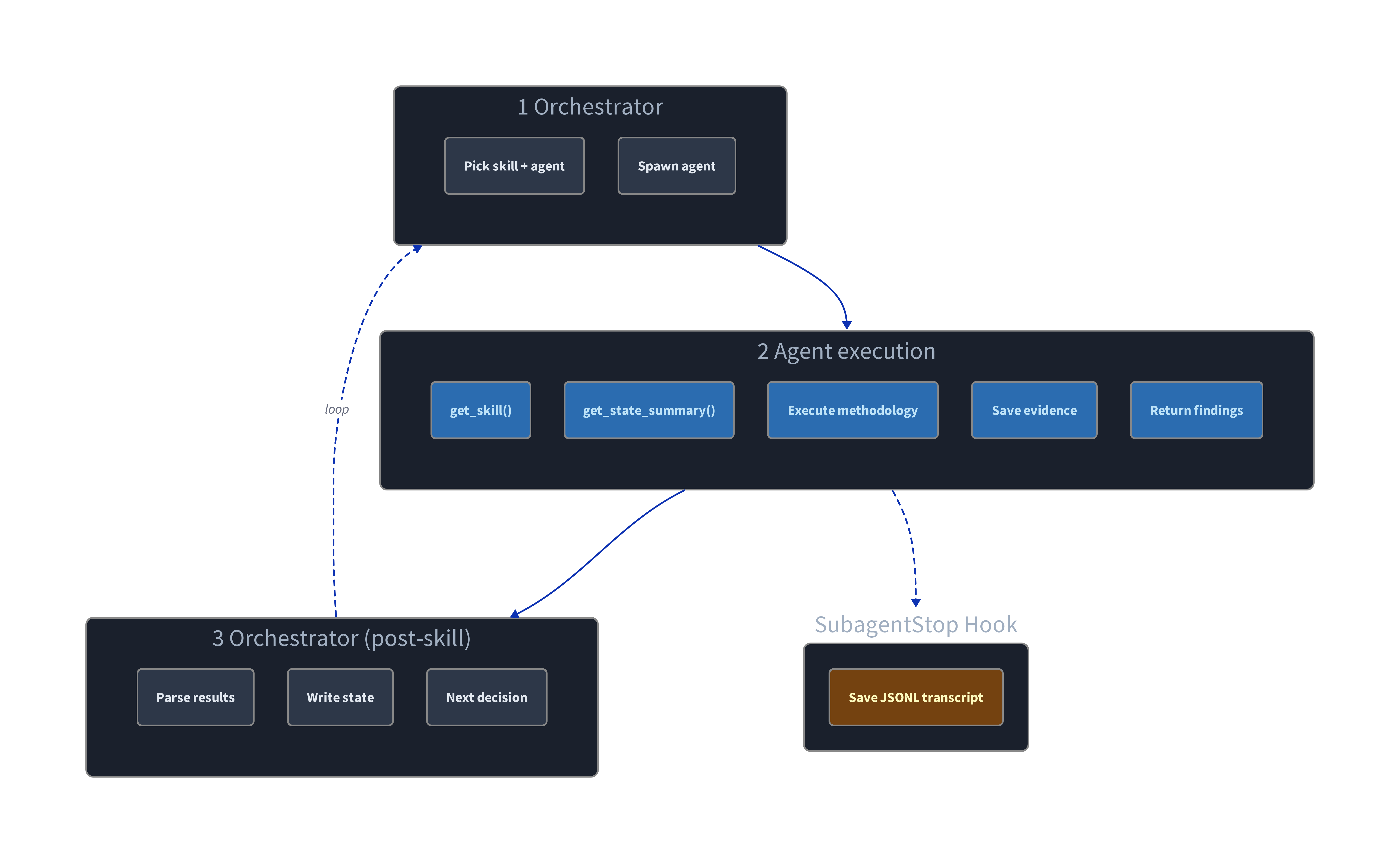
red-run attempts to solve this problem with the orchestrator skill - the single skill that is loaded into context at startup. orchestrator acts as the main function and is intended to run on the Opus model with adaptive thinking enabled.
First and foremost, orchestrator is responsible for tracking the overall state of the engagement in a SQLite database during execution. A frequently updated state tracking database allows orchestrator to reconnect all the necessary dots after the lobotomization that is the compaction process. In fact, lengthy engagements can be resumed from an entirely fresh session with minimal productivity loss.
The second and equally important job of the orchestrator is skill and agent routing. Routing guides the engagement through its various phases - enumeration, initial access, lateral movement, pivoting, privilege escalation, exfiltration. Whenever the orchestrator learns new information about the target, it decides which skills to invoke and which agents to task next, in one of two ways:
Using a hardcoded decision tree. Examples:
new target discovered? →
network-reconweb service found? →
web-discoveryKerberos? →
ad-discovery
Searching for a relevant skill using retrieval-augmented generation (RAG). Example:
network-recon-agentfinds Apache Tomcat AJP connectororchestratorhas no hardcoded logic for this scenarioorchestratorsends query “Apache Tomcat AJP connector” toskill-routerMCP serverskill-routerresponds withajp-ghostcatskill ranked as most relevant, with a 76% similarity scoreorchestratortasksweb-exploit-agentwith theajp-ghostcatskill
Agents can be dispatched to work in parallel on separate tasks whenever potential attack paths diverge, and the orchestrator or human operator can always step in to redirect off-task agents, as needed. When agents report back, the orchestrator makes new routing decisions based on the updated target datapoints.
Agents write interim findings to the state database mid-task, so the orchestrator can detect new discoveries and delegate follow-up agents within minutes rather than waiting for the original agent to complete. For example, if ad-discovery encounters a new web service, the orchestrator learns about it and can task web-discovery immediately, not ten minutes later, once ad-discovery finishes its full run. This iterative workflow of agentic tasking keeps the Opus-powered main context window free for operator interaction, and the main loop continues ad infinitum until all operator-defined objectives are achieved.
Retrospectives
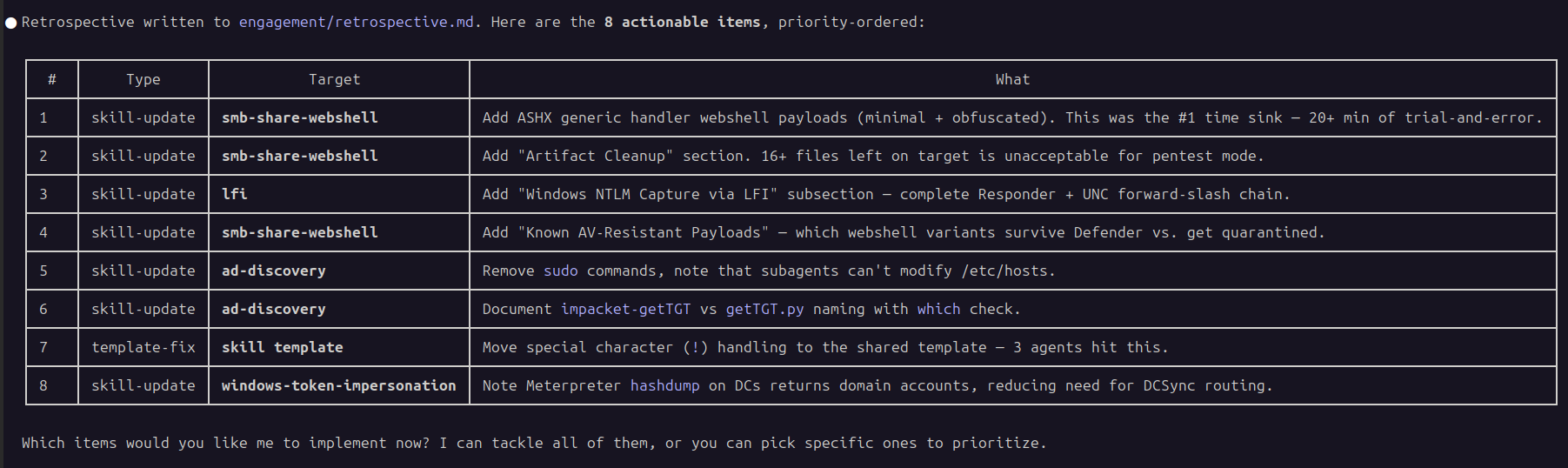
Post-engagement is where red-run really starts to shine. The retrospective skill runs in the main context window and reviews the steps taken during the engagement. Skill routing decisions are analyzed. Agent behaviors are examined, down to the individual commands executed during agentic tasks. Gaps in payloads and methodology are identified. Manual interventions are noted.
Claude produces a prioritized list of items that can include skill methodology updates, agent improvements, new skills to build, and orchestrator routing fixes.
Warning: the retrospective skill leads to some existential questions, like “why am I here at all?”

Future State
red-run has evolved from a simple offensive security skill library into a RAG-backed on-demand agent dispatcher with a hierarchical planning system that prefers parallelization (say that three times fast). It is slowly becoming a push-button utility that can navigate most infrastructure-style CTFs from IP address to root flag or die trying (or until you run out of money to throw at Anthropic). Its effectiveness is amplified in the hands of a skilled operator who can nudge agents in the right direction when they inevitably jump down rabbit holes or make mistakes.
That said, red-run is still VERY MUCH a proof-of-concept (PoC). The orchestrator, in its current form, is a fancy CTF solver and is not meant for client-facing engagements. It is designed to complete labs and improve itself over time through retrospectives, similar to how a junior penetration tester might learn.
The orchestrator skill will evolve and mature. red-run could one day be made entirely modular, enabling an operator to swap out a CTF-focused orchestrator for a client-safe version that prefers stealth and evasion, or a version that trains operators on new techniques. Skills will expand to include cloud infrastructure, operational technology (OT), and reverse engineering (RE). MCP servers will be built to support custom command-and-control (C2) infrastructure, phishing activity, and local models for data processing and reporting.
We are in the very early days of agentic coding, but the implications for the offensive security community cannot be understated. It would not be surprising to see authorized penetration testing engagements soon supplemented with semi-autonomous orchestrated agents that assist human operators. It would be equally unsurprising to see these types of tools deployed during real attacks by threat actors with bad intentions.
Demo
To illustrate the speed with which these tools can move, here is red-run vs Flight.HTB (WARNING: spoilers ahead).
Full disclosure: Flight.HTB has been used as a test bed for several recent red-run features and routing improvements. Claude navigated the correct path on its first attempt, but not this quickly.
This run took 1 hour and 24 minutes in real time, but red-run has spent as many as 3 hours and as few as 45 minutes solving this box. CTF testing has exposed the truly indeterminate nature of LLMs. Agents take slightly different paths through the same box each iteration, even with identical operator prompts. Sometimes agents get stuck on mundane problems like clock skew - a task with explicit troubleshooting steps in their loaded skill. They often ignore agent- and skill-level instructions like “DO NOT download tools from the internet” due to prompt pressure. And these agents, loaded with Claude-built skills, have absolutely no OPSEC awareness. Claude has no chill. red-run will light up your SOC, all while your sensitive data is sent off to Anthropic servers. Do not run this in production.
Closing Thoughts
Even with the latest models and meticulously-written skills, “AI” is just another tool in the arsenal for both attackers and defenders (for now). Anyone who uses LLMs daily knows that they continue to make outright bad decisions from time to time. When positioned as a threat-actor targeting your production environment, those bad decisions can become instantly catastrophic. Indeed, a new type of threat actor has been created - overly trusting and inexperienced agentic tool users.
LLMs are not deterministic. The same input is never guaranteed to produce the same output. This is why skilled humans must be kept in the loop whenever an LLM might execute code on an asset - to supervise and to enforce constraints.
It is unclear what offensive security jobs will look like in a year, let alone in five years, given the current pace of change. Human operators will certainly continue to execute hands-on-keyboard tasks, but those tasks will evolve (as they always have).
Afterthoughts
At first glance, it might appear that we’ve somehow “jailbroken” the model, but this is not the case. “Jailbreaking” typically implies that safety features were bypassed in order to trick the LLM into doing something it was not meant to do. Claude Code is supposed to help with security testing. It says so right there in the system prompt:
IMPORTANT: Assist with authorized security testing, defensive security, CTF challenges, and educational contexts. Refuse requests for destructive techniques, DoS attacks, mass targeting, supply chain compromise, or detection evasion for malicious purposes. Dual-use security tools (C2 frameworks, credential testing, exploit development) require clear authorization context: pentesting engagements, CTF competitions, security research, or defensive use cases. [4]
Security researchers and ethical hackers need this functionality in Claude Code in order to keep pace with threats. With sufficient resources, advanced threat actors can build and run their own sophisticated attack-oriented models on their own hardware, with no flimsy guardrails attempting to limit them to “authorized security testing”. Advanced threat actors do not need Anthropic.